本文共 8455 字,大约阅读时间需要 28 分钟。
目录
一、栈的定义
栈:栈是一种“操作受限”的线性表。栈的主要操作有2个:入栈(在栈顶插入一个数据)、出栈(在栈顶删除一个数据)。
受限一定不好吗?
非也。从功能上来说,数组/链表可以替代栈,但它们暴露了太多的操作接口,使用时不可控;此外,特定的结构是对特定的场景的抽象,正是因为现实中有某种特殊场景,我们才提出栈这种特殊的结构。



那么,什么时候适合使用栈呢?
当某个数据集合只涉及在一端插入、删除数据,并且满足后进先出、先进后出的特性时,就可以使用栈。
二、如何实现一个栈
栈结构有两种实现方式:数组、链表。
采用数组比较方便,但需要考虑栈的最大容量的问题,大小没有取一个合适的值,既可能申请过多空间造成浪费,又可能使用过程中栈空间不足。后者可以采用动态扩容数组来缓解一下。
而采用链表无需考虑容量问题,不过因为每个数据多了个地址域,所以一般消耗内存空间更多。
两种方式没有绝对的好坏,需要视情况而定。有时要用空间换取时间上的高效,有时则尽可能节省空间,跑得慢一点无所谓。
下面的表格是各种栈的push、pop操作的时间复杂度。其中,动态数组栈在大部分时间做push操作时,都只需常量时间。而当数组满了之后,再做push时,则申请一个更大的数组(一般是原来数组的大小的2倍),然后把原数组的数据都搬过去。这时的时间与原数组的最大容量n相关,即,时间为c*n。但是,由于我们是经过n-1次常数级别的push操作之后,才碰到一次n的一次方级别的操作,所以我们可以把n的一次方级别的push所花的时间,均摊给其他n-1次push操作。这么一来,总体的push操作的时间复杂度仍然是O(1)。这种方法叫做均摊分析法。
| 数组栈 | 链栈 | 动态数组栈 | |
| push操作 | O(1) | O(1) | O(1) |
| pop操作 | O(1) | O(1) | O(1) |
1、数组实现
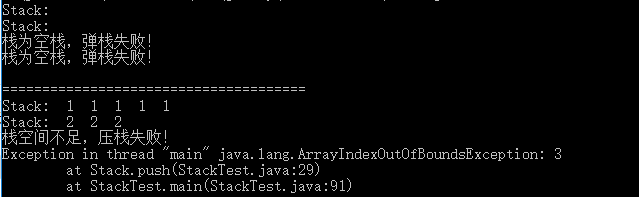
class Stack { private int[] arr; private int top = -1; private int capacity = 5; public Stack() { this.arr = new int[capacity];// 默认的话则创建大小为5的栈 } public Stack(int n) { this.arr = new int[n]; // 创建栈时,指定栈的大小 this.capacity = n; } // Push public void push(int x) { if (top == capacity - 1) { System.out.println("栈空间不足,压栈失败!"); } arr[++top] = x; } // Pop public int pop() { if (top == -1) { System.out.println("栈为空栈,弹栈失败!"); return -10000; } return top--; //注意:我们只是让top往下移而已,事实上该数据还是在原来的位置,只是我们认为它不在逻辑的栈内部。 } // 判断栈是否为空 public boolean isEmpty() { if (top == -1) { return true; } return false; } // 查看栈顶的元素 public int top() { if (top == -1) { System.out.println("栈为空栈,没有栈顶元素"); return -10000; } return arr[top]; } // 打印、查看栈的所有元素 public void printAll() { System.out.print("Stack: "); for (int i=top; i>=0; i--) { System.out.print(arr[i]+" "); } System.out.println(); }}public class StackTest { public static void main(String[] args) { Stack stack1 = new Stack(); Stack stack2 = new Stack(3); //1、 stack1.printAll(); stack2.printAll(); stack1.pop(); // 检查空栈执行pop操作时 是否报错 stack2.pop(); //2、 System.out.print("\n======================================\n"); for (int i=0; i<5; i++) { stack1.push(1); } for (int i=0; i<3; i++) { stack2.push(2); } stack1.printAll(); stack2.printAll(); stack1.push(100); // 检查满栈执行push操作时 是否报错 stack2.push(200); }} 注意上面的pop()中,我们只是让top往下移而已,事实上该数据还是在原来的位置,并没有被销毁,只是我们认为它不在逻辑的栈内部而已。如,下面有个空栈,当我们将2、10、5依次push进去后,执行一次pop操作时,5仍然在标号为2的位置,只不过它再也不是栈中的元素了。由此,我们也可以看出,在数组实现的栈中,top的作用是非常关键的。它起到一个边界的作用,在top之内都是栈的空间,在top之外则不是(至于我们申请栈时,指定的空间大小capacity,其实并不是栈的空间大小,而是栈所能达到的最大空间)。top与栈的各种操作紧密联系。

测试结果如下面所示:
2、链表实现
如果采用链表来实现栈的话,由于没有空间限制,我们在做push操作时,就不用再考虑栈是否满的问题了。所以只需要考虑栈为空的问题。
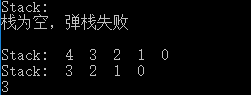
class StackNode { public int data; public StackNode next; public StackNode() { } public StackNode(int data) { this.next = null; this.data = data; }}class StackBasedOnLinkList { StackNode head = null;// 头引用 public int count = 0; // 计数栈的元素个数 StackBasedOnLinkList() { } // push public void push(int data) { StackNode node = new StackNode(data); //采用头插法 插入数据 node.next = head; head = node; count = count + 1; } // pop public int pop() { if (head == null) { System.out.println("栈为空,弹栈失败"); // return -10000; } StackNode p = head; head = head.next; //让要删除的结点p 地址域为null,指向它的引用也为null 这样就可以被垃圾回收器回收了 int data = p.data; p.next = null; p = null; count = count - 1; return data; } // 判断栈是否为空 public boolean isEmpty() { if (head == null) { // 判断条件可改为 count == 0 return true; } return false; } // 查看栈顶的元素 public int top() { if (head == null) { System.out.println("栈为空栈,没有栈顶元素"); return -10000; } return head.data; } // 打印、查看栈的所有元素 public void printAll() { StackNode pointer = head; // 新建一个遍历引用,否则head跑到后面,就不便于以后的操作了 System.out.print("Stack: "); while (pointer != null) { System.out.print(pointer.data+" "); pointer = pointer.next; } System.out.println(); }}public class LinkedStackTest { public static void main(String[] args) { StackBasedOnLinkList stack = new StackBasedOnLinkList(); //1、 stack.printAll(); //stack.pop(); stack.pop(); //2、 System.out.println(); for (int i=0; i<5; i++) { stack.push(i); } stack.printAll(); stack.pop(); stack.printAll(); System.out.println(stack.top()); }} 输出结果如下图所示:
有三个地方需要注意:
(1)在上面Stack类的push()、pop()中,我们都是在头部插入、删除一个元素,为什么不采用尾插法在尾部插入、删除元素呢?
这是因为,我们采用的链表是普通的单链表(只带头引用,而没有尾引用),在头部操作由于有头引用,我们的push、pop操作的时间复杂度都为O(1)。而如果在尾部操作的话,由于没有尾引用,我们需要从头遍历到尾部,这样push、pop操作的时间复杂度就变为O(n)了。
(2)在上面Stack类的printAll()中,我们新建一个引用StackNode pointer = head,然后利用它来遍历整个栈(整条链)。这么做的原因是:栈的绝大部分操作都是围绕栈顶(在数组栈中是top下标,在链栈中是head引用),数组栈中遍历栈的操作printAll()并不会改变top值,而在链栈如果我们用head来遍历,那么遍历完成时head将指向栈中最里面的元素,而我们以后还要经常用指向栈顶的head引用完成各种操作,这样就得不偿失了。所以我们用一个新的引用来代替head引用去遍历。
写到这里,我突然想到,现实中也有很多这种遍历的场景。比如军训时教官从一排队伍的队头检阅到队尾,这就类似printAll中一个引用不断跑到不同的元素那里。还有,地铁安检时人们排着队通过安检、做纸带实验时纸带通过打点计时器、生产流水线,这些则与前面的场景有所不同:负责检查、打点的部分是静止不动的。但是归根结底,这两种遍历的场景本质上是相同的。
(3)在Stack类的pop()中,如果我们不返回弹栈时的值,则可以这么写。注意判空之外的其他代码要写在else代码块,否则有可能报出空引用异常。
public void pop() { if (head == null) { System.out.println("栈为空,弹栈失败"); } else { StackNode p = head; head = head.next; p.next = null; p = null; count = count - 1; }} 三、栈的应用场景
栈可以应用到诸多场景:(1)函数调用、递归(其实是特殊的函数调用);(2)编辑器、浏览器的撤销操作;(3)括号匹配
下面举几个例子。
1、使用栈来反转表或集合
(1)反转字符串(顺序结构)
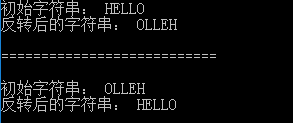
初始字符串为“HELLO”,则逆转后的字符串为“OLLEH”。ReverseString类中有两个逆转方法,其中reverseString()采用栈结构(利用其先进后出的特性),reverseString1()采用传统的遍历方法,将首末对应位置的两个元素进行对换。
import java.util.Stack;public class ReverseString { public static void main(String[] args) { String string1 = new String("HELLO"); System.out.println("初始字符串: "+string1); string1 = reverseString(string1); System.out.println("反转后的字符串: "+string1); System.out.println("\n===========================\n"); System.out.println("初始字符串: "+string1); string1 = reverseString1(string1); // 两次逆转,得到最初的字符串 System.out.println("反转后的字符串: "+string1); } public static String reverseString(String str) { Stack stack = new Stack (); String str1 = ""; for (int i=0; i 输出结果如下图所示,两次逆转之后,字符串变为初始字符串“HELLO”
(2)反转链表(链式结构)
初始链表为:1,2,3,4,5 逆转之后为5,4,3,2,1
import java.util.Stack;class Node { public int data; public Node next; public Node() {} public Node(int data) { this.data = data; this.next = null; } // 打印链表的所有元素 形参传入的是头结点 public static void printAll(Node node) { while(node.next != null) { System.out.print(node.next.data+" "); node = node.next; } }}public class ReverseLinkedList { public static void main(String[] args) { Node head = new Node(); // 头结点 不含数据 for (int i=5; i>=1; i--) { // 采用头插法,创建一个带头结点的链表:1,2,3,4,5,null Node node = new Node(i); node.next = head.next; head.next = node; } System.out.print("初始链表: "); Node.printAll(head); System.out.print("\n反转后的链表: "); head = reverseLinkedList(head); Node.printAll(head); } public static Node reverseLinkedList(Node head) { //Stack stack = new Stack (); Stack stack = new Stack<>(); if (head.next == null) { // 如果是空链表,则直接返回null return null; } Node temp = head; while (temp.next != null) { stack.push(temp.next); temp = temp.next; } Node temp2 = head; while (!stack.isEmpty()) { //如果栈不为空,则不断弹栈 Node node = stack.pop(); temp2.next = node; temp2 = temp2.next; node.next = null; } return head; }} 输出结果如下图所示:
![]()
小结:利用栈反转字符串(顺序结构),比较适合那种字符串长度较短、对时间空间使用不敏感的场景。比如上面的reverseString1()方法,我们采用传统的方式(首末对应位置数据交换)的循环只需遍历 n/2次(n是字符串长度),而采用栈的方式,则需要遍历n次。
而利用栈反转链表,则比较整洁直观,效率也比较高。
2、括号匹配
读入一个表达式(字符串形式),判断表达式中的括号是否按照()、{}、[]严格匹配
我们用字符栈实现,主要利用栈的先进后出特性,步骤如下:
新建一个字符栈,从头到尾一一读取各个位置的字符
(1)若该字符是左括号(、{、[,则压入栈;
(2)若该字符是右括号,
1)判断栈是否为空栈,若是则提示“该字符串的括号没有匹配”;若否,则将栈顶元素弹栈
2)判断弹出的栈顶元素是否与该字符匹配,若是则提示“该字符串匹配成功”;否则提示“该字符串的括号没有匹配”
import java.util.Stack; // 这里使用jdk自带的栈import java.util.Scanner; public class BalanceParentheses { public static void main(String[] args) { String string1 = new String("{(1+2)*5+[100*1]}"); areParanthesesBalanced(string1); System.out.println(); System.out.println(); String string2 = new String("{(1+2)*5+]100*1[}"); areParanthesesBalanced(string2); // 控制台输入第三个表达式 Scanner scan = new Scanner(System.in); String string3; string3 = scan.next(); areParanthesesBalanced(string3); } // 判断两个括号是否匹配 public static boolean arePair(char opening, char closing) { if ( opening=='(' && closing==')' ) { return true; } else if ( opening=='{' && closing=='}' ) { return true; } else if ( opening=='[' && closing==']' ) { return true; } else { return false; } } // 判断字符串是否匹配 public static boolean areParanthesesBalanced(String expression) { Stack stack = new Stack (); for (int i=0; i 运行结果如下所示:

转载地址:http://tbnii.baihongyu.com/